Overview
Asian Conference on Machine Learning (ACML) 2019will be held in WINC AICHI, Nagoya, Japanfrom November 17 to 19, 2019. AutoSpeechis one of the competitions in main conferenceprovided by 4Paradigm, ChaLearn and Google.The competition has been launched at CodaLab, please follow the link to participa'te:
https://autodl.lri.fr/competitions/48 In the last decade, deep learning (DL) has achieved remarkable success in speech-related tasks, e.g., speaker verification, language Identification and emotion classification. However, in practice, it is very difficult to switch between different tasks without human efforts. To address this problem, Automated Deep Learning (AutoDLhttps://autodl.chalearn.org) is proposed to explore automatic pipeline to train an effective DL model given a specific task requirement. Since its proposal, AutoDL have been explored in various applications, and a series of AutoDL competitions, e.g., Automated natural language processing (AutoNLP) and Automated computer vision (AutoCV), have been organized by 4Paradigm, Inc. and ChaLearn (sponsored by Google). These competitions have drawn a lot of attention from both academic researchers and industrial practitioners.In this challenge, we further propose the Automated Speech (AutoSpeech) competition which aims at proposing automated solutions for speech-related tasks. This challenge is restricted to multi-label classification problems, which come from different speech classification domains. The provided solutions are expected to discover various kinds of paralinguistic speech attribute information, such as speaker, language, emotion, etc, when only raw data (speech features) and meta information are provided. There are two kinds of datasets, which correspond to public and private leaderboard respectively. Five public datasets (without labels in the testing part) are provided to the participants for developing AutoSpeech solutions. Afterward, solutions will be evaluated with five unseen datasets without human intervention. The results of these five datasets determine the final ranking.
This is the first AutoSpeech competition, and that focuses on speech categorization this time, which will pose new challenges to the participants, as listed below: - How to automatically discover various kinds of paralinguistic information in spoken conversation? - How to automatically extract useful features for different tasks from speech data? - How to automatically handle both long and short duration speech data? - How to automatically design effective neural network structures? - How to build and automatically adapt pre-trained models?
Additionally, participants should also consider: - How to automatically and efficiently select appropriate machine learning model and hyper-parameters? - How to make the solution more generic, i.e., how to make it applicable for unseen tasks? - How to keep the computational and memory cost acceptable?
Platform
Participants should log in ourplatformto start the challenge. Please follow the instructions inplatform [Get Started]to get access to the data, learn the data format and submission interface, and download the starting-kit.
This page describes the datasets used in AutoSpeech challenge. 15 speech categorization datasets are prepared for this competition.Five practice datasets, which can be downloaded, are provided to the participants so that they can develop their AutoSpeech solutions offline. Besides that, anotherfive validation datasetsare also provided to participants to evaluate the public leaderboard scores of their AutoSpeech solutions. Afterward, their solutions will be evaluated withfive test datasetswithout human intervention.Dataset
Each provided dataset is from one of five different speech classification domains: Speaker Identification, Emotion Classification, Accent Recognition, Language Identification and Music Genre Classification. In the datasets, the number of classes is greater than 2 and less than 100, while the number of instances varies from hundredes to thousands. All the audios are first converted to single-channel, 16-bit streams at a 16kHz sampling rate for consistency, then they are loaded by librosa and dumped to pickle format (A list of vectors, which contains all train or test audios in one dataset). Note that, datasets contain both long audios and short audios without padding.Components
All the datasets consist of content file, label file and meta file, where content file and label file are split into train parts and test parts:-
Content fileAll the datasets consist of audio file, label file and meta file, where audio file and label file are split into train parts and test parts: Audio file ({train,test}.pkl) contains the samples of the audios, which format is a list of vectors.
Example:
[ [-1.2207031e-04, 3.0517578e-05, -1.5258789e-04, ..., -8.8500977e-04, -8.5449219e-04, -1.3732910e-03]), [ 9.1552734e-05, 7.0190430e-04, 1.0375977e-03, ..., -7.6293945e-04, 2.7465820e-04, 1.0375977e-03]), [ 1.8920898e-03, 1.6784668e-03, 1.4648438e-03, ..., 3.0517578e-05, -2.7465820e-04, -3.0517578e-04]), [0.02307129, 0.02386475, 0.02462769, ..., 0.02420044, 0.02410889, 0.02429199]), [ 6.1035156e-05, 1.2207031e-04, 4.5776367e-04, ..., -1.2207031e-04, -6.1035156e-04, -3.6621094e-04]), [0.03787231, 0.03686523, 0.03723145, ..., 0.03497314, 0.03594971, 0.0350647 ]), ..., ]
-
Label file({train, dataset_name}.solution) consists of the labels of the instances in one-hot format. Note that each of its lines corresponds to the corresponding line number in the content file.
Example:1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
-
Meta file(meta.json) is a json file consisted of the meta information about the dataset. Descriptions of the keys
in meta file:class_num : number of classes in the dataset train_num : the number of training instances test_num : the number of test instances time_budget : the time budget of the dataset, 1800s for all the datasets
-
Example:
{ "class_num": 10, "train_num": 428, "test_num": 107, "time_budget": 1800 }
Datasets Credits
We thank the following sources for providing us with these wonderful datasets:
- A. Nagrani*, J. S. Chung*, A. Zisserman VoxCeleb: a large-scale speaker identification datasetINTERSPEECH, 2017.
-Weinberger, Steven. (2015).Speech Accent Archive. George Mason University. Retrieved fromhttp://accent.gmu.edu
-http://www.expressive-speech.net/, Berlin emotional speech database
-CSS10: A Collection of Single Speaker Speech Datasets for 10 Languageshttps://arxiv.org/abs/1903.11269
-D. Ellis (2007).Classifying Music Audio with Timbral and Chroma Features,Proc. Int. Conf. on Music Information Retrieval ISMIR-07,Vienna, Austria, Sep. 2007.
Rules
This challenge hasthree phases. The participants are provided with five practice datasets which can be downloaded, so that they can develop their AutoSpeech solutions offline. Then, the code will be uploaded to the platform and participants will receive immediate feedback on the performance of their method at another five validation datasets. Afterfeedback phaseterminates, we will have anothercheck phase, where participants are allowed to submit their codeonly onceon private datasets in order to debug. Participants won't be able to read detailed logs but they are able to see whether their code report errors. Last, in theFinalPhase,Participants' solutionswill be evaluated on five test datasets. The ranking in the final phase will count towards determining the winners.
Code submitted is trained and tested automatically, without any human intervention. Code submitted onfeedback (resp. final) phaseis run on all five feedback (resp. final) datasets in parallel on separate compute workers, each one with its own time budget.
The identities of the datasets used for testing on the platform are concealed.The data are provided in araw form(no feature extraction) to encourage researchers to use Deep Learning methods performing automatic feature learning, although this is NOT a requirement. All problems aremulti-class classificationproblems. The tasks are constrained by thetime budget (30 minutes/dataset).
Here is some pseudo-code of the evaluation protocol:
# For each dataset, our evaluation program calls the model constructor:
# The total time of import Model and initialization of Model should not exceed 20 minutes
from model import Model
M =Model(metadata=dataset_metadata)
remaining_time budget = overall_time_budget
# Ingestion program calls multiple times train and test:
repeat until M.done_training or remaining_time_budget < 0
{
# Only the runtime of the train and test function will be counted into the time budget
start_time = time.time() M.train (training_data, remaining_time_budget)
remaining_time_budget -= time.time() - start_time
start_time = time.time()
results = M.test(test_data, remaining_time_budget)
remaining_time_budget -= time.time() - start_time
# Results made available to scoring program (run in separate container)
save(results)
}
It is the responsibility of the participants to make surethat neither the "train" nor the "test" methods exceed the “remaining_time_budget”. The method “train” can choose to manage its time budget such that it trains in varying time increments.Note that, the model will be initialized only one time during the submission process, so the participants can control the model behavior at each train step by its member variables.There is a pressure that it does not use all "overall_time_budget" at the first iteration because we use the area under the learning curve as the metric. Besides that, the total time of import Model and initialization of Model should not exceed 20 minutes.
Metrics
The participants can train in batches of pre-defined duration to incrementally improve their performance until the time limit is attained. In this way, we can plot learning curves:"performance" as a function of time. Each time the "train" method terminates, the "test" method is called and the results are saved, so the scoring program can use them, together with their timestamp.
For multi-class problems,each label/class is considered a separate binary classification problem, and we compute the normalized AUC (or Gini coefficient)
2 * AUC - 1
as the score for each prediction, here AUC is the average of the usualarea under ROC curve(ROC AUC) of all the classes in the dataset.
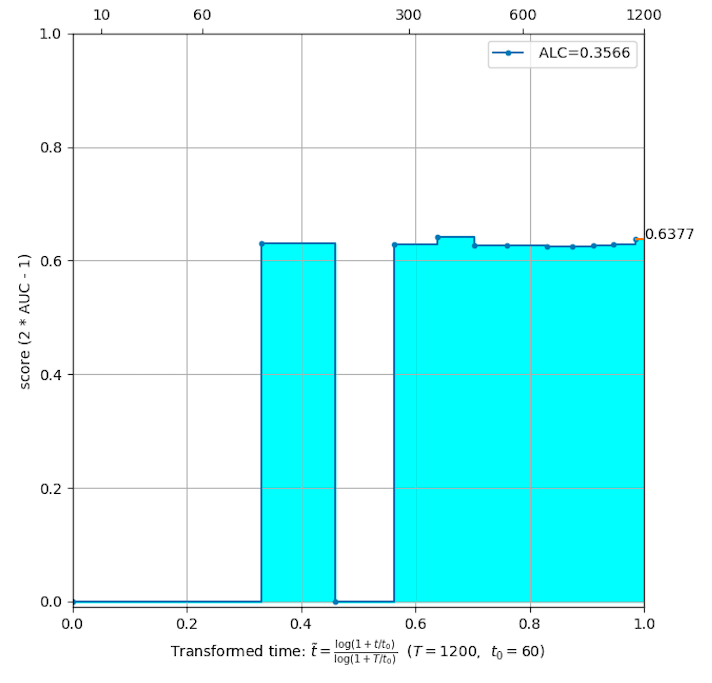
For each dataset, we compute theArea under Learning Curve (ALC). The learning curve is drawn as follows:
- at each timestamp t, we compute s(t), the normalized AUC (see above) of themost recentprediction. In this way, s(t) is astep functionw.r.t time t;
-
in order to normalize time to the [0, 1] interval, we perform a time transformation by
where T is the time budget (of default value 1800 seconds = 30 minutes) and t0 is a reference time amount (of default value 60 seconds). -
then compute the area under learning curve using the formula
we see that s(t) is weighted by 1/(t + t0)), giving a stronger importance to predictions made at the beginning of the learning curve.
After we compute the ALC for all 5 datasets, theoverall rankingis used as the final score for evaluation and will be used in the leaderboard. It is computed by averaging the ranks (among all participants) of ALC obtained on the 5 datasets.
Examples of learning curves:
More details about submission and evaluation can be found on theplatform [Get Started - Evaluation].
Terms & Conditions
Please find the challenge rules on theplatform website [Get Started - Challenge Rules].
Prizes
- 1st Place: $2,000
- 2ndPlace: $1,500
- 3rdPlace: $500
Timeline
Beijing Time (UTC+8)
-
Sep 16th, 2019, 16:59: Beginning of the feedback Phase, the release of practice datasets. Participants can start submitting codes and obtaining immediate feedback in the leaderboard.
- Oct 07th, 2019, 23:59: Real Personal Identification
-
Oct 14th, 2019, 23:59: End of the feedback Phase.
- Oct 15th, 2019, 00:00: Beginning of the check Phase.
-
Oct 18th, 2019, 19:59: End of the check Phase.
- Oct 18th, 2019, 20:00: Beginning of the final Phase.
-
Oct 20th, 2019, 20:00: Re-submission deadline.
- Oct 22nd, 2019, 20:00: End of the final Phase.
Note that the CodaLab platform uses UTC time format, please pay attention to the time descriptions elsewhere on this page so as not to mistake the time points for each phase of the competition.
About
Pleasecontact the organizersif you have any problem concerning this challenge.
Sponsors



Advisors
- Wei-Wei Tu, 4Pardigm Inc., China, (Coordinator, Platform Administrator, Data Provider, Baseline Provider, Sponsor)tuweiwei@4paradigm.com
-Tom Ko, Southern University of Science and Technology, China (Advisor)tomkocse@gmail.com
- Isabelle Guyon, Universté Paris-Saclay, France, ChaLearn, USA, (Advisor, Platform Administrator)guyon@chalearn.org
- Qiang Yang, Hong Kong University of Science and Technology, Hong Kong, China, (Advisor, Sponsor)qyang@cse.ust.hk
Committee (alphabetical order)
- Jingsong Wang,4Paradigm Inc., China, (Dataset provider, baseline)wangjingsong@4paradigm.com
- Ling Yue,4Paradigm Inc., China, (Platform Administrator)liushouxiang@4paradigm.com
- Shouxiang Liu,4Paradigm Inc., China, (Admin)yueling@4paradigm.com
- Xiawei Guo, 4Paradigm Inc., China, (Admin)guoxiawei@4paradigm.com
- Zhengying Liu, U. Paris-Saclay; U. PSud, France, (Platform Provider)zhengying.liu@inria.fr
- Zhen Xu,4Paradigm Inc., China, (Admin)xuzhen@4paradigm.com
Organization Institutes
AboutAutoML
Previous AutoML Challenges:
About 4Paradigm Inc.
Founded in early 2015,4Paradigmis one of the world’s leading AI technology and service providers for industrial applications. 4Paradigm’s flagship product – the AI Prophet – is an AI development platform that enables enterprises to effortlessly build their own AI applications, and thereby significantly increase their operation’s efficiency. Using the AI Prophet, a company can develop a data-driven “AI Core System”, which could be largely regarded as a second core system next to the traditional transaction-oriented Core Banking System (IBM Mainframe) often found in banks. Beyond this, 4Paradigm has also successfully developed more than 100 AI solutions for use in various settings such as finance, telecommunication and internet applications. These solutions include, but are not limited to, smart pricing, real-time anti-fraud systems, precision marketing, personalized recommendation and more. And while it is clear that 4Paradigm can completely set up a new paradigm that an organization uses its data, its scope of services does not stop there. 4Paradigm uses state-of-the-art machine learning technologies and practical experiences to bring together a team of experts ranging from scientists to architects. This team has successfully built China’s largest machine learning system and the world’s first commercial deep learning system. However, 4Paradigm’s success does not stop there. With its core team pioneering the research of “Transfer Learning,” 4Paradigm takes the lead in this area, and as a result, has drawn great attention of worldwide tech giants.
About ChaLearn
ChaLearnis a non-profit organization with vast experience in the organization of academic challenges. ChaLearn is interested in all aspects of challenge organization, including data gathering procedures, evaluation protocols, novel challenge scenarios (e.g., competitions), training for challenge organizers, challenge analytics, resultdissemination and, ultimately, advancing the state-of-the-art through challenges.
About Google
Googlewas founded in 1998 by Sergey Brin and Larry Page that is a subsidiary of the holding company Alphabet Inc. More than 70 percent of worldwide online search requests are handled by Google, placing it at the heart of most Internet users’ experience. Its headquarters are in Mountain View, California. Google began as an online search firm, but it now offers more than 50 Internet services and products, from e-mail and online document creation to software for mobile phones and tablet computers. It is considered one of the Big Four technology companies, alongside Amazon, Apple and Facebook.

